Word Embeddings
How words become vectors that can capture semantic similarity, direction, and reusable language structure.
Background
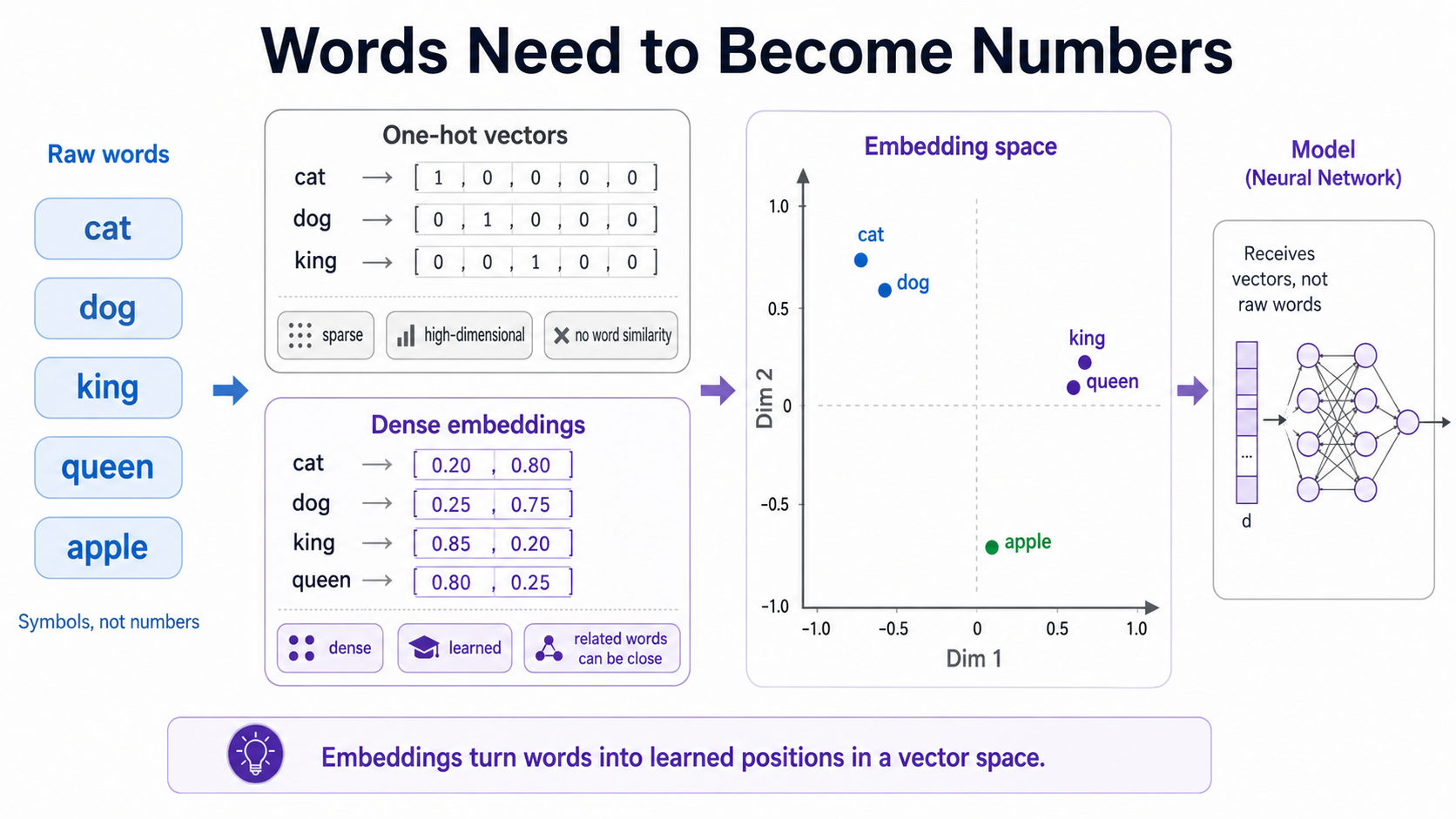
Neural networks cannot work directly with the word cat as a word. Models expect numbers, but text is symbolic.
A simple one-hot encoding can assign each word an ID, yet that representation makes every term equally distant. There is no reason for the model to know that cat and dog are related while cat and apple are not.
Word embeddings solve this problem by giving each word a dense vector learned from data. In this space, similar words appear closer together, allowing the network to infer meaning from distances.
Idea
The core idea of word embeddings is that every word becomes a point in a multi-dimensional meaning space.
Words used in similar contexts tend to end up near one another. The absolute numbers in a vector are not a dictionary definition; the information lies in the relative positions and directions between vectors.
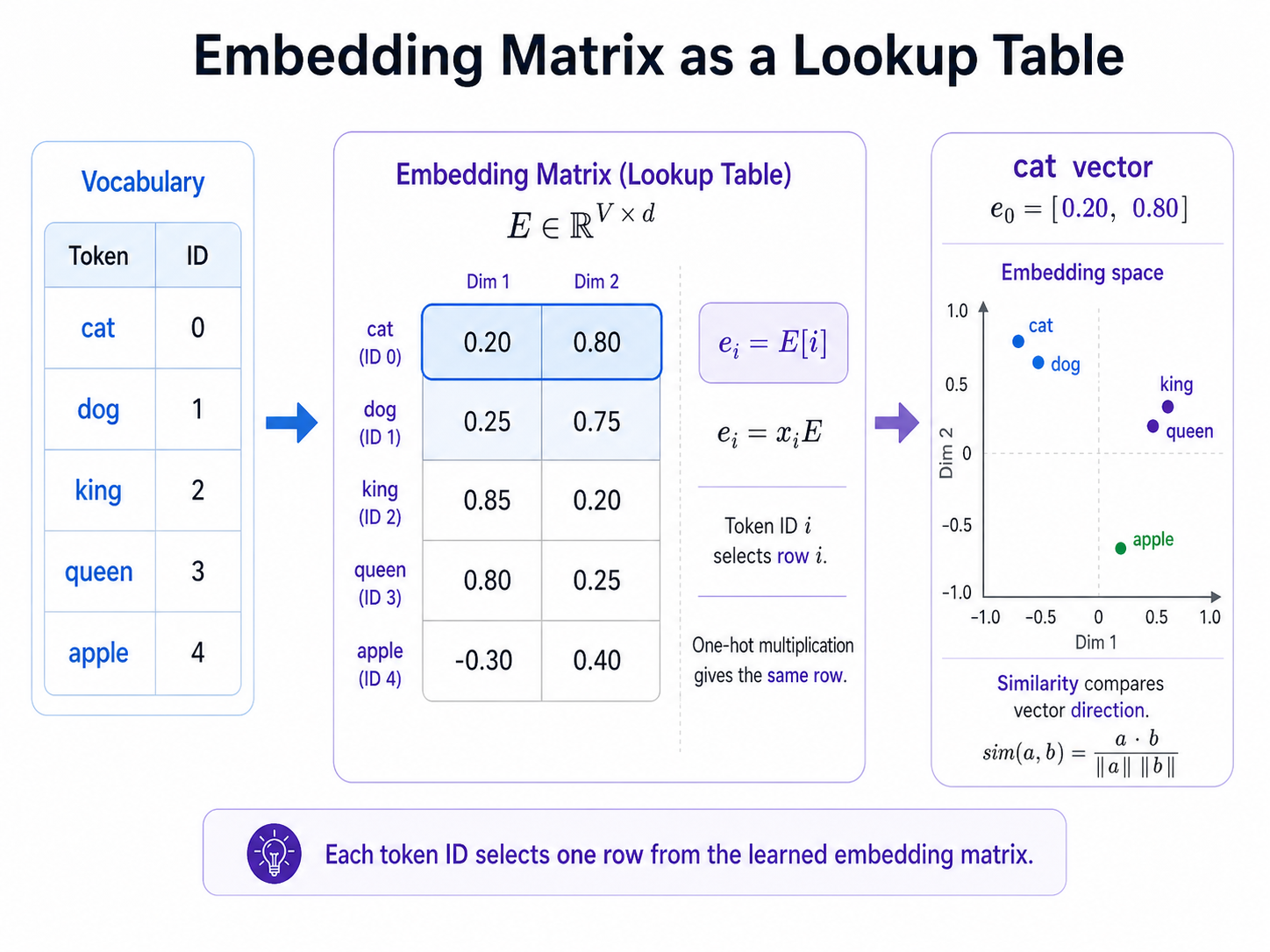
The embedding layer inside a neural network can be viewed as a learned lookup table mapping token IDs to vectors.
Formula
The embedding matrix has one row per token and d columns for the embedding dimension.
To obtain the vector for token ID i, take the i-th row of E.
If the token is represented as a one-hot vector, lookup can be written as matrix multiplication.
Cosine similarity is a common way to compare two embedding vectors.
Symbols
- V: size of the vocabulary.
- d: embedding dimension, or the length of each vector.
- E: the embedding matrix of shape V by d.
- i: token ID or index of a word in the vocabulary.
- E[i] or e_i: the embedding vector for token i.
- x_i: one-hot vector with a 1 at position i and zeros elsewhere.
- a and b: two embedding vectors being compared.
- sim(a,b): cosine similarity between vectors a and b.
Example
Consider a tiny vocabulary: cat, dog, king, queen, and apple. Assign token IDs as cat = 0, dog = 1, king = 2, queen = 3, apple = 4.
For illustration, imagine a two-dimensional embedding matrix where cat is [0.20, 0.80], dog is [0.25, 0.75], king is [0.85, 0.20], queen is [0.80, 0.25], and apple is [-0.30, 0.40].
In this simplified space, cat and dog lie close together; king and queen are near each other; apple is far from both groups.
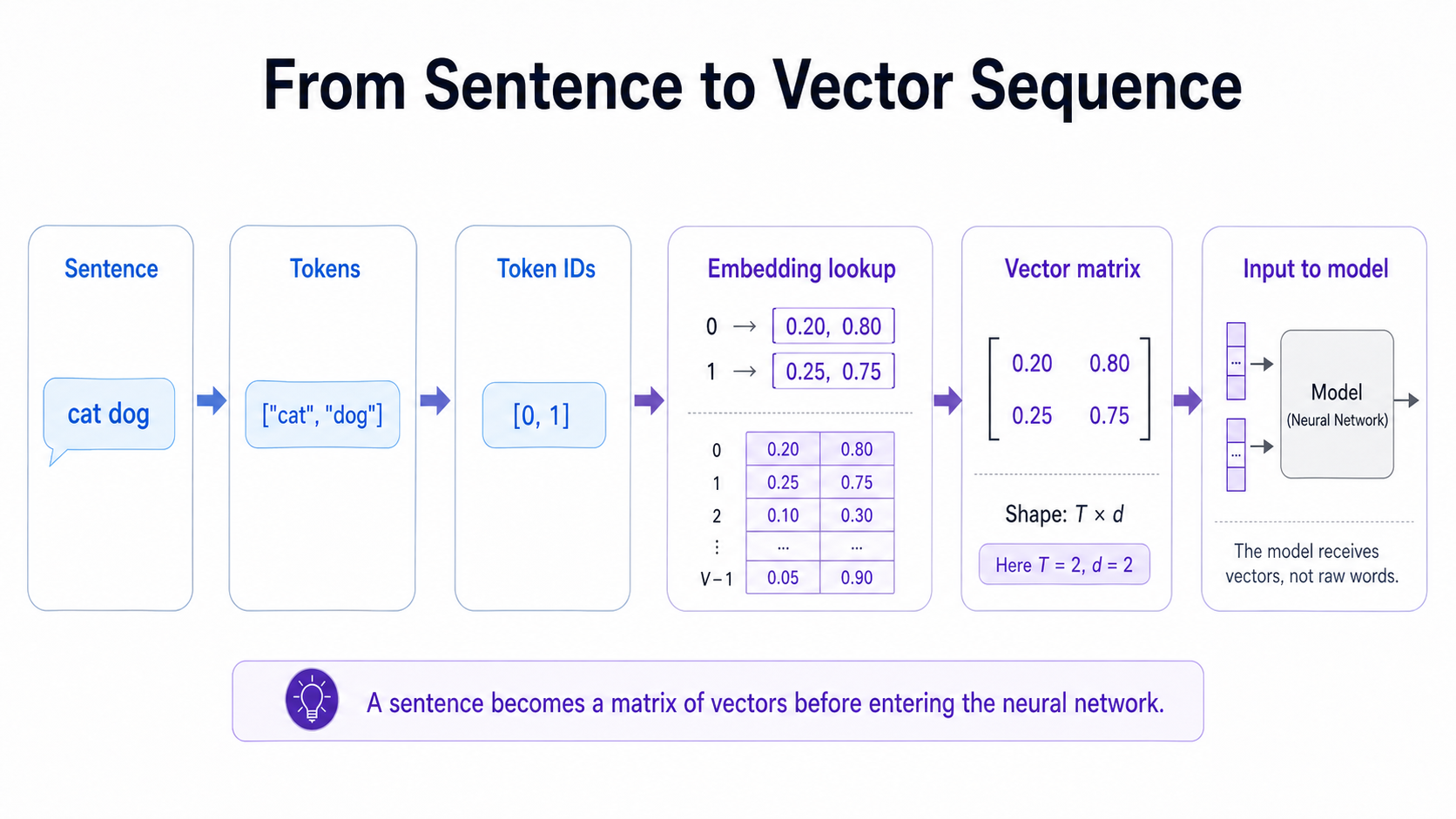
Now take the short sentence cat dog. Tokenising and converting to IDs gives [0, 1]. Looking up each ID yields a 2 by d matrix of vectors, which is what the neural network receives instead of the raw words.
Real embeddings have hundreds of dimensions and are learned from large corpora. This 2D example is a teaching tool, not a trained model.
Workflow
- Build a vocabulary: collect all distinct tokens from the data and assign each an integer ID.
- Convert words to IDs: tokenize a sentence and replace each word with its ID.
- Store embeddings in a matrix: initialize or load an embedding matrix E of size V by d.
- Look up vectors: for each token ID i, take the row E[i] to get its embedding vector.
- Create a matrix for the sentence: a sentence of T tokens becomes a T by d matrix of vectors.
- Feed into the model: pass the sequence of vectors into the rest of the neural network.
- Train and update: backpropagation updates the embedding matrix so vectors move to more useful positions.
Pros
- Turns symbolic words into numerical vectors a neural network can process.
- Dense vectors are much smaller than sparse one-hot vectors.
- Words used in similar contexts often acquire similar vectors, enabling the model to generalize.
- Pretrained embeddings can transfer language knowledge to new tasks.
Cons
- Classic embeddings assign one vector per word, ignoring multiple meanings.
- Rare or unseen words may receive poor vectors.
- Embeddings can encode and amplify biases present in training data.
- A 2D plot is a projection; real embeddings live in high dimensions.
- High similarity in vector space does not mean the model truly understands the concept.
Takeaway
Word embeddings give each word a learned position in a continuous vector space. By mapping words to numbers, they allow neural networks to compare, combine, and learn from text.
The relative positions and directions among vectors encode semantic relationships, but those numbers are learned approximations, not definitions. Embeddings provide a powerful yet simple bridge between language and computation.