Transfer Learning
How pretrained features can be reused, adapted, and fine-tuned for a smaller or more specific target task.
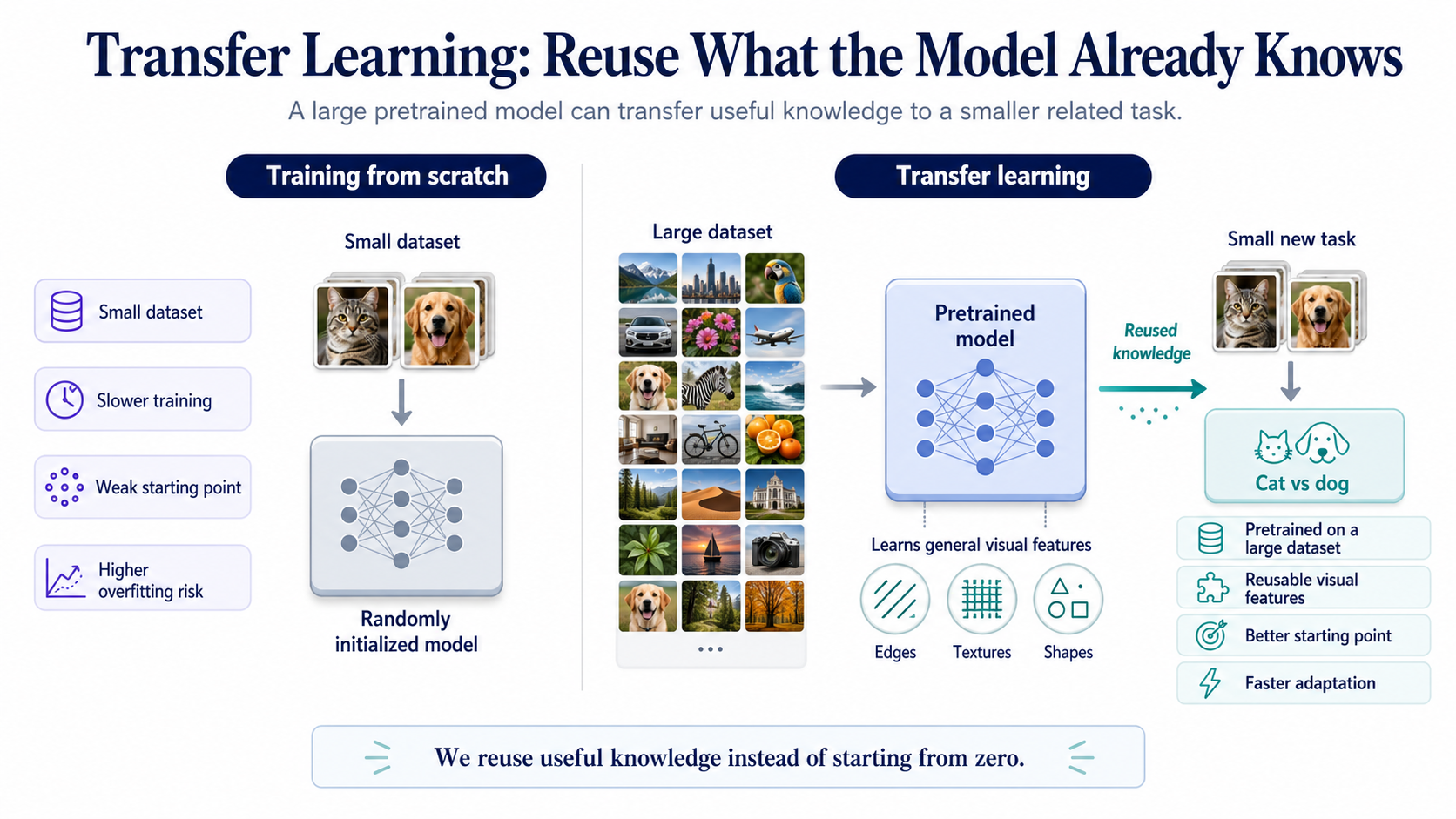
Background
Training a deep model from scratch usually needs a large labeled dataset, strong compute, and many rounds of tuning.
Many real projects only have a small amount of labeled data, so starting from random weights can be slow and unreliable.
Transfer learning exists because knowledge learned from one large task can often help another related task. Instead of teaching a model from zero, we start with a pretrained model and adapt it to the new problem.
Idea
A pretrained model has already learned useful patterns from a large dataset. We reuse most of that model as a feature extractor, then replace the old prediction layer with a new head for our task.
At first, we often freeze the earlier layers so their weights do not change. Then we train only the new head, because it needs to learn the new labels.
Later, we may fine-tune some deeper layers carefully if the new task needs more adaptation. The mental model is simple: reuse general knowledge, learn only what is new.
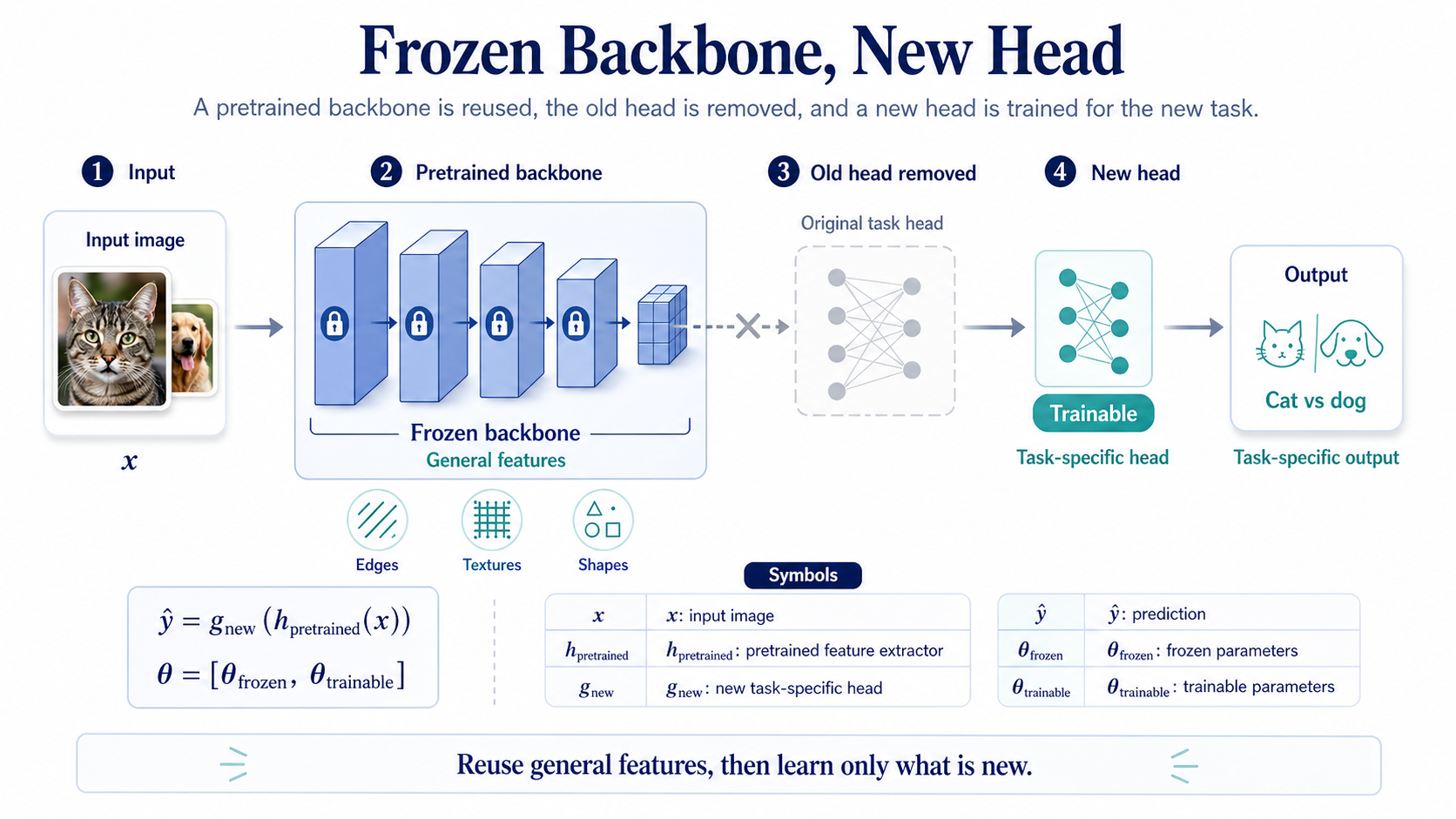
Formula
The pretrained model turns the input into reusable features.
The new head maps pretrained features to the new task prediction.
Frozen parameters stay fixed, while trainable parameters are updated for the new task.
Symbols
- x: input example, such as an image.
- h_pretrained: pretrained feature extractor.
- g_new: new task-specific head.
- y-hat: prediction for the new task.
- theta_frozen: parameters kept fixed during training.
- theta_trainable: parameters updated for the new task.
Example
Suppose a beginner wants to build a cat vs dog classifier, but only has 500 labeled images. Training a CNN from scratch with only 500 images may cause the model to memorize the training set instead of learning useful visual patterns.
A better starting point is to use a model pretrained on ImageNet. The model has already seen millions of images and learned general visual features such as edges, textures, fur-like shapes, and object parts.
The old ImageNet head predicts 1,000 classes, so we remove it. We keep the convolutional backbone and add a new binary classification head that predicts only cat or dog.
At first, the backbone is frozen and only the new head is trained. Later, we may unfreeze the last few blocks and fine-tune them with a small learning rate.
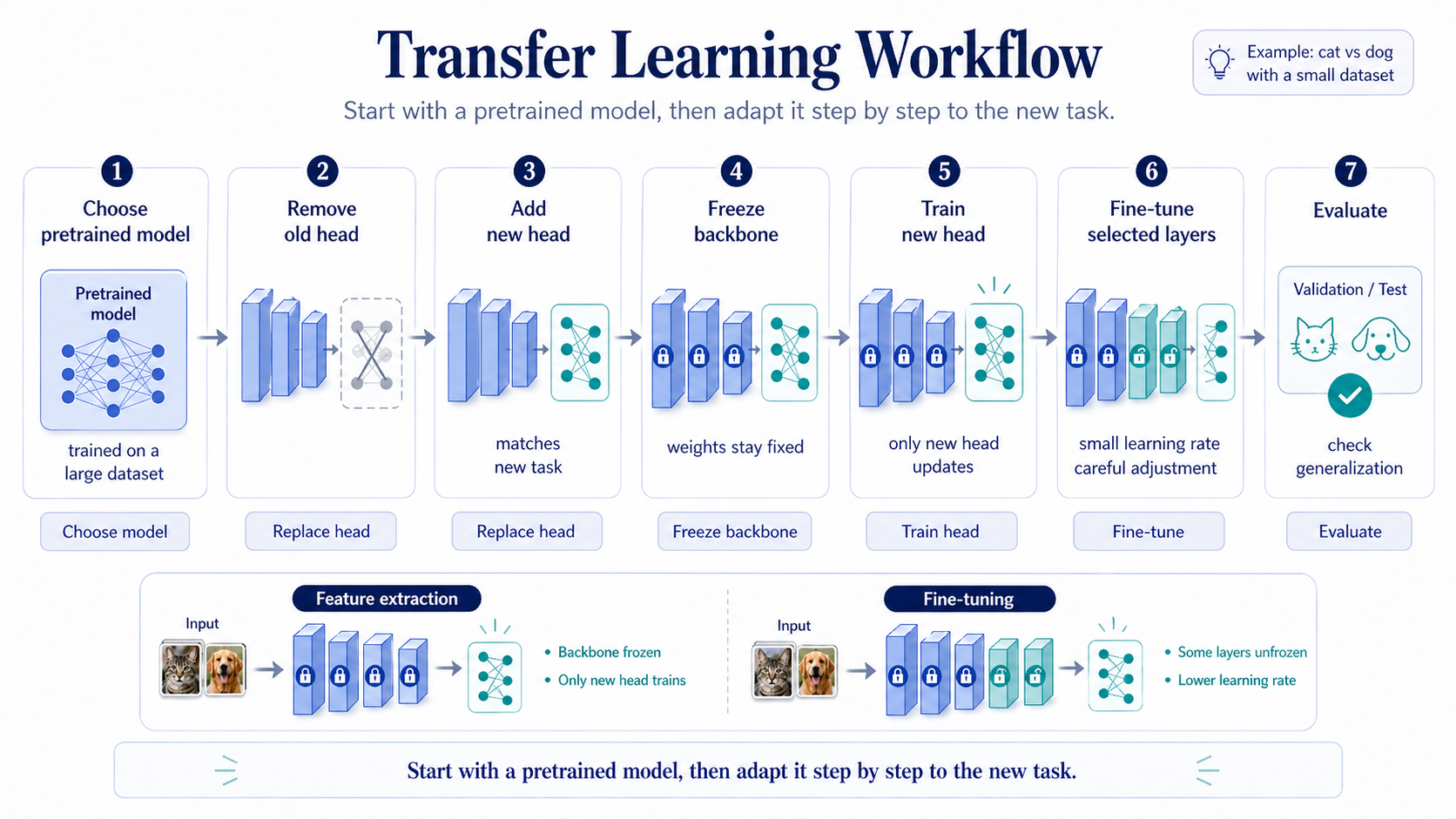
Workflow
- Choose a pretrained model trained on a large dataset.
- Remove or ignore the old task head.
- Keep the pretrained backbone as a feature extractor.
- Add a new head for the new task.
- Freeze the backbone first to protect useful pretrained features.
- Train the new head.
- Fine-tune selected layers if the task needs more adaptation.
- Evaluate on validation or test data.
Pros
- Needs less labeled data.
- Trains faster than starting from scratch.
- Often works better on small datasets.
- Reuses general visual features.
- Saves compute.
Cons
- Works best when source and target tasks are related.
- Can fail when the new domain is very different.
- Fine-tuning too much can overfit.
- Freezing too much can underfit.
- Pretrained models may carry bias.
Takeaway
Transfer learning is about reusing useful knowledge instead of starting from zero.
The model keeps general features from a pretrained backbone and learns a new task-specific head. It is especially useful when the new dataset is small but related to what the pretrained model has already learned.