Self-Attention vs RNN vs CNN
Compare how sequence order, receptive field, parallelism, and context flow differ across the three families.
Background
Natural language, time-series, and other sequential data are not just lists of independent items. The meaning of a word like it in a sentence depends on surrounding words.
Without a way to share information across positions, a model cannot resolve pronouns, capture long-term dependencies, or detect patterns that unfold over time.
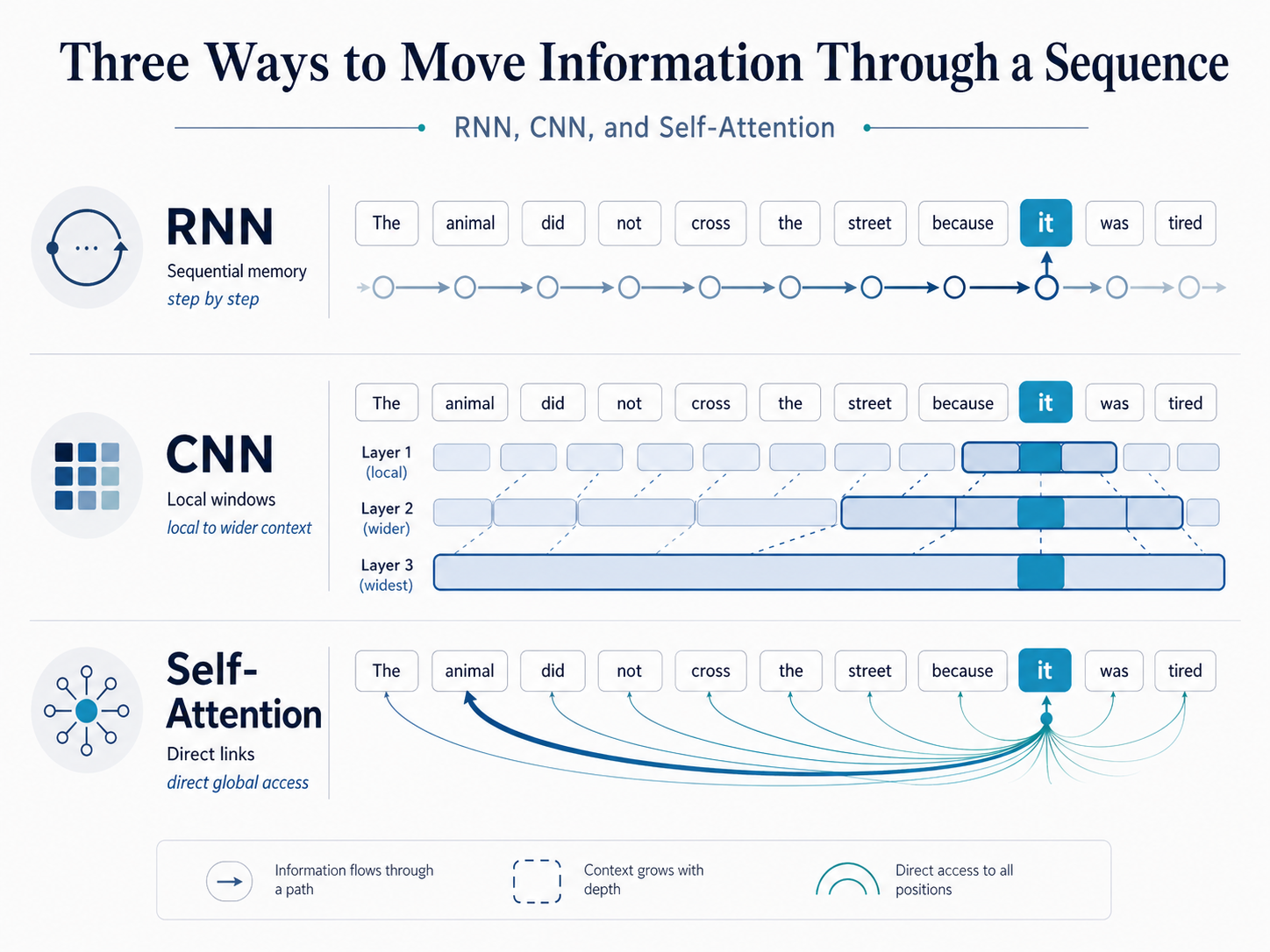
RNNs, CNNs, and self-attention all answer the same question: how should information move across a sequence?
Idea
RNNs use sequential memory. Information moves step by step, and each hidden state carries a running summary of what has been seen so far.
CNNs use local window expansion. Convolutional filters first read nearby tokens, and deeper layers expand the receptive field.
Self-attention uses direct global interaction. Each token compares itself with every other token and decides which positions matter most.
Formula
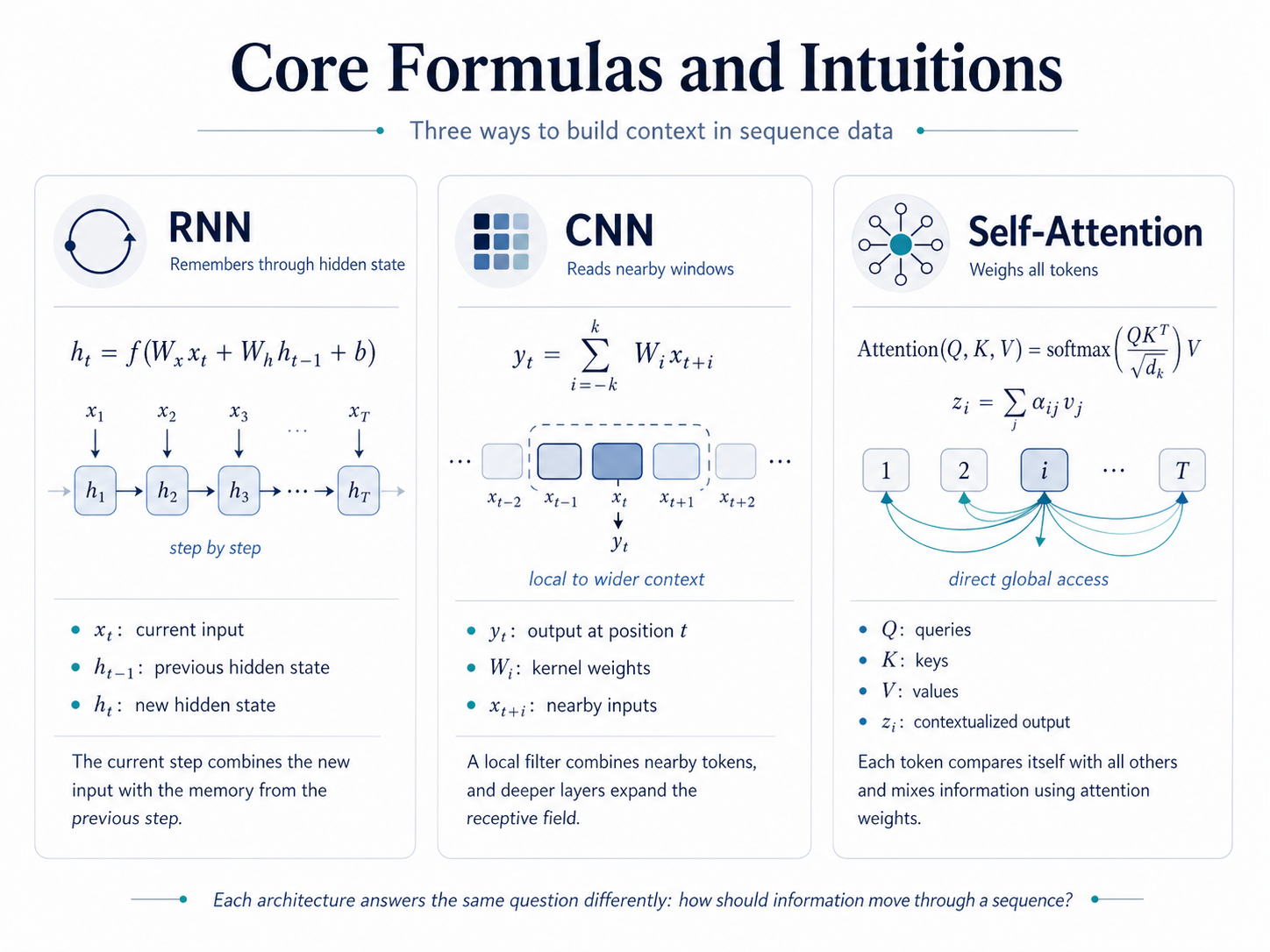
RNNs update a hidden state from the current input and the previous hidden state.
CNNs combine tokens inside a local sliding window.
Self-attention compares queries and keys, then combines values using learned weights.
For one token, attention weights decide how much each other token contributes to its context vector.
Symbols
- x_t: input vector at position t.
- h_t: hidden state at position t in an RNN.
- W_x and W_h: learnable weight matrices for input and hidden state.
- y_t: output of a CNN at position t.
- W_i: convolution filter weight for offset i.
- Q, K, V: query, key, and value matrices.
- q_i, k_j, v_j: query for token i and key/value for token j.
- d_k: dimension of the key vectors.
- alpha_ij: attention weight from token i to token j.
- z_i: output context vector at position i.
Example
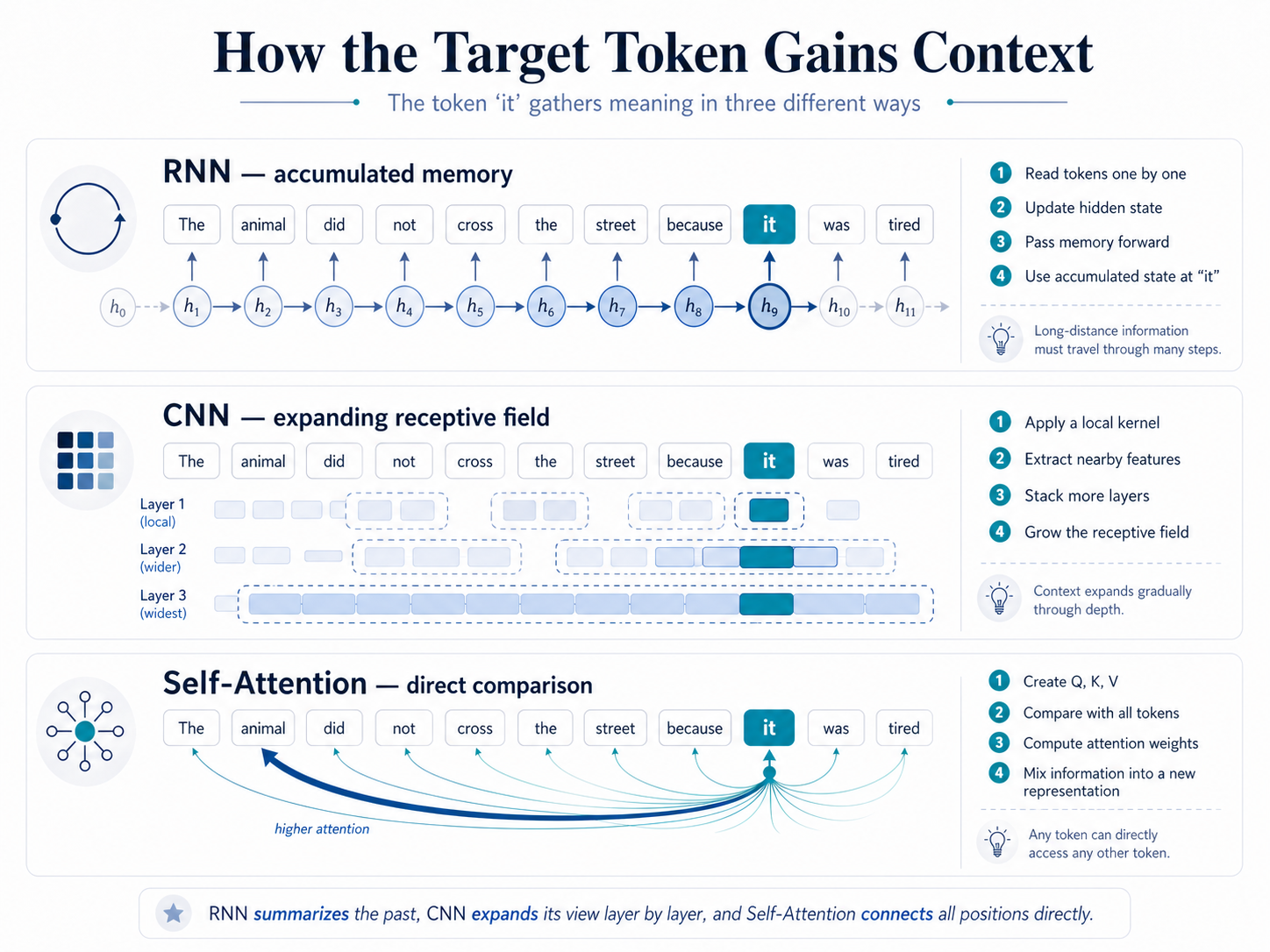
Consider the sentence: The animal did not cross the street because it was tired. The word it refers to the animal, not the street.
An RNN carries information forward through hidden states. By the time the model reaches it, earlier words influence the hidden state indirectly, but their influence can fade as the sequence grows.
A CNN with a small kernel first sees local neighbours such as because it was. To connect it to animal, the model needs stacked layers or larger receptive fields.
Self-attention lets the token it directly assign high weight to animal and lower weight to unrelated words. This direct link makes long-distance dependencies easier to capture.
Workflow
- RNN: read tokens one by one, update the hidden state, and use the accumulated state to contextualize the target token.
- CNN: slide a kernel over local windows, compute local combinations in parallel, and stack layers to expand the receptive field.
- Self-attention: compute query, key, and value vectors for each token, compare all token pairs, softmax the scores, and combine value vectors into context vectors.
- For self-attention, positional information must be added so the model knows which token came first.
Pros & Cons
| Method | Trade-off |
|---|---|
| RNN | Natural for ordered and streaming data, but difficult to parallelize and weaker on very long dependencies. |
| CNN | Efficient and good at local patterns, but distant dependencies require depth, dilation, or larger kernels. |
| Self-attention | Directly links all token pairs and parallelizes well, but has quadratic cost and needs positional encoding. |
Takeaway
RNNs, CNNs, and self-attention are three complementary ways to build context in sequence data.
An RNN carries information step by step, a CNN expands from local windows through depth, and self-attention lets each token look directly at every other token.
The right choice depends on the task, the sequence length, and computational constraints.