RMSProp
Learn how RMSProp gives each parameter an adaptive step size by tracking recent squared gradients.
Background
Plain SGD uses one global learning rate for every parameter. This is simple, but it can be hard to tune when different parameters have very different gradient scales.
If one direction has very large gradients, SGD may take unstable steps in that direction. If another direction has small gradients, SGD may move too slowly there.
RMSProp solves this by tracking recent squared gradients. Instead of using the raw gradient directly, it divides each gradient component by a running root-mean-square scale.
RMSProp is different from Momentum. Momentum remembers direction. RMSProp remembers scale.
Idea
The core idea is: large recent gradients create a larger denominator, which creates a smaller effective step.
SGD uses one learning rate. RMSProp creates a different effective learning rate for each parameter by looking at the recent squared-gradient magnitude.
This makes RMSProp helpful on badly scaled surfaces, where one parameter direction can otherwise dominate the update.
Important Formulas
Mini-batch gradient input. RMSProp starts with the same gradient as SGD.
Plain SGD applies the same learning rate to every parameter.
Squared-gradient accumulator. It stores recent gradient magnitude, not direction.
RMSProp scales the gradient element-wise before updating the parameters.
Effective learning rate for one parameter j.
Expanded memory view: recent squared gradients matter more, while older ones fade.
Layer-wise RMSProp accumulator for weight gradients.
Layer-wise RMSProp accumulator for bias gradients.
Layer-wise weight update.
Layer-wise bias update.
Symbols
- g_t: mini-batch gradient at step t.
- eta: global learning rate.
- s_t: running average of recent squared gradients.
- rho: decay rate for the accumulator.
- epsilon: small value for numerical stability.
- odot: element-wise multiplication.
- eta_eff,j: effective learning rate for parameter j.
Pros
| Pros | Why it helps |
|---|---|
| Adaptive per-parameter scaling | RMSProp adjusts each update based on recent gradient magnitude. |
| Helpful on badly scaled surfaces | It reduces unstable movement in directions with consistently large gradients. |
| Less dependent on one perfect learning rate | The global learning rate still matters, but each parameter gets its own effective step size. |
| Important bridge to Adam | Adam uses a similar squared-gradient accumulator as part of its adaptive scaling. |
| Works with noisy mini-batches | Recent squared-gradient memory smooths sudden gradient-scale changes. |
Cons
| Cons | Why it matters |
|---|---|
| Adds hyperparameters | Rho, eta, and epsilon must be chosen sensibly. |
| Can shrink useful directions too much | Large accumulated squared gradients can make a parameter's effective step very small. |
| No direction memory | RMSProp rescales gradients, but Momentum is still the idea that smooths direction. |
| Less transparent than SGD | The effective learning rate changes per parameter over time. |
| Often replaced by Adam | Adam combines Momentum-like direction memory with RMSProp-like scaling. |
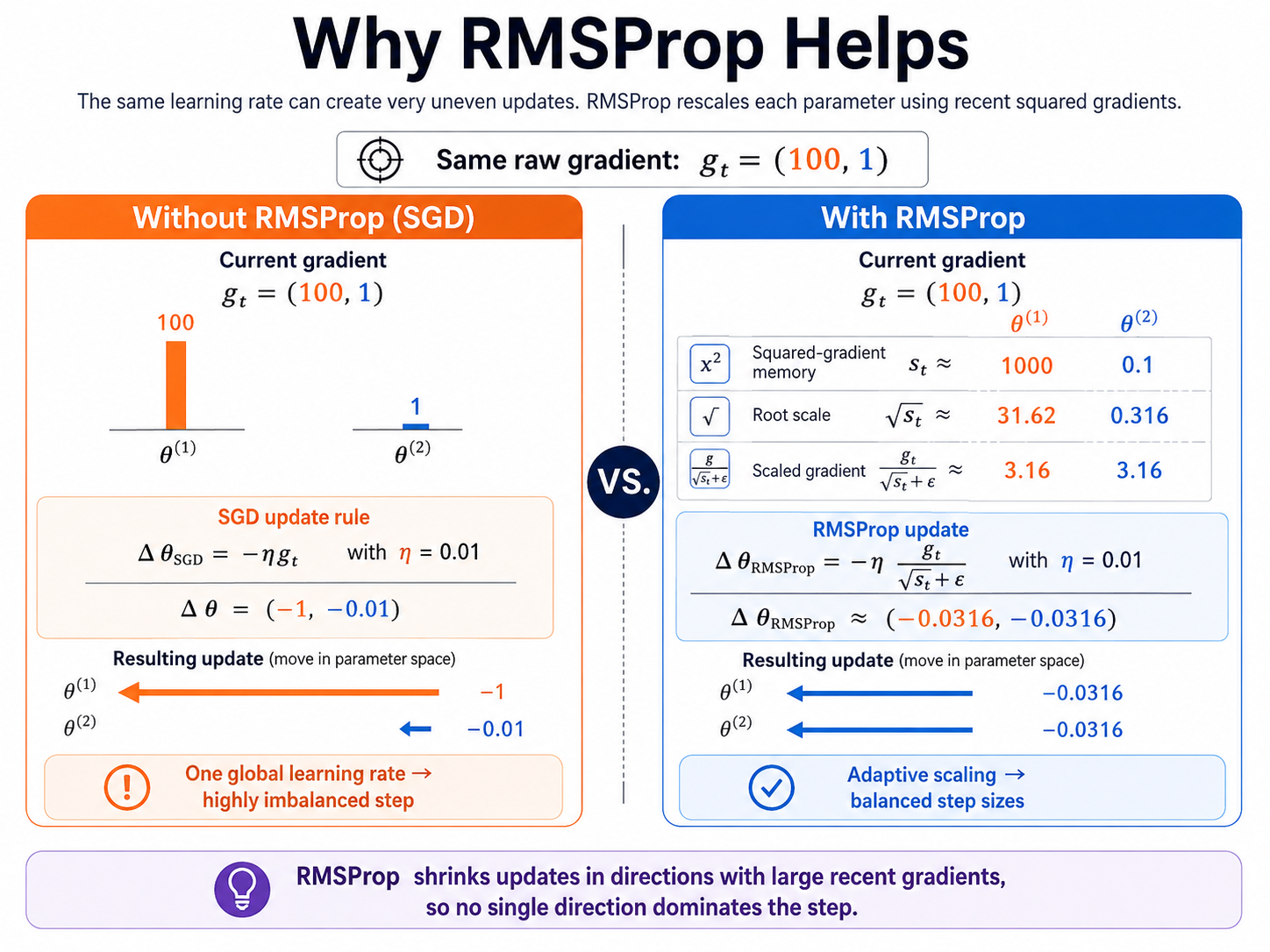
Quick Example
Suppose two parameters have the same global learning rate but very different gradient magnitudes. Let theta_t = (0, 0), g_t = (100, 1), and eta = 0.01.
Plain SGD would update by eta g_t = (1, 0.01), so the first parameter dominates the movement.
With RMSProp, use rho = 0.9, s_{t-1} = (0, 0), and ignore epsilon only for this simplified calculation. The squared-gradient accumulator becomes s_t = (1000, 0.1), so the root scale is approximately (31.62, 0.316).

Example Calculation
Plain SGD produces a highly imbalanced update.
RMSProp stores recent squared-gradient magnitude.
The larger-gradient direction receives a larger denominator.
The scaled gradient becomes balanced.
The large-gradient direction no longer dominates the step.
Common Mistakes
- Thinking RMSProp changes how g_t is computed. It does not; it changes how the gradient is scaled before the update.
- Confusing RMSProp with Momentum. Momentum remembers past gradient directions; RMSProp remembers past squared-gradient magnitudes.
- Forgetting that the square, square root, and division are element-wise operations.
- Thinking RMSProp removes the need for learning-rate tuning. The global learning rate eta still matters.
- Confusing RMSProp with Adam. Adam tracks both a first moment and a second moment, then applies bias correction.
Takeaway
RMSProp gives each parameter an adaptive step size by tracking recent squared gradients.
Directions with consistently large gradients receive smaller effective steps, while directions with smaller gradients are not suppressed as much.
Momentum remembers direction. RMSProp remembers scale. Adam later combines both ideas.