Residual Block / ResNet Intuition
Why skip connections help information and gradients move through deeper networks more reliably.
Background
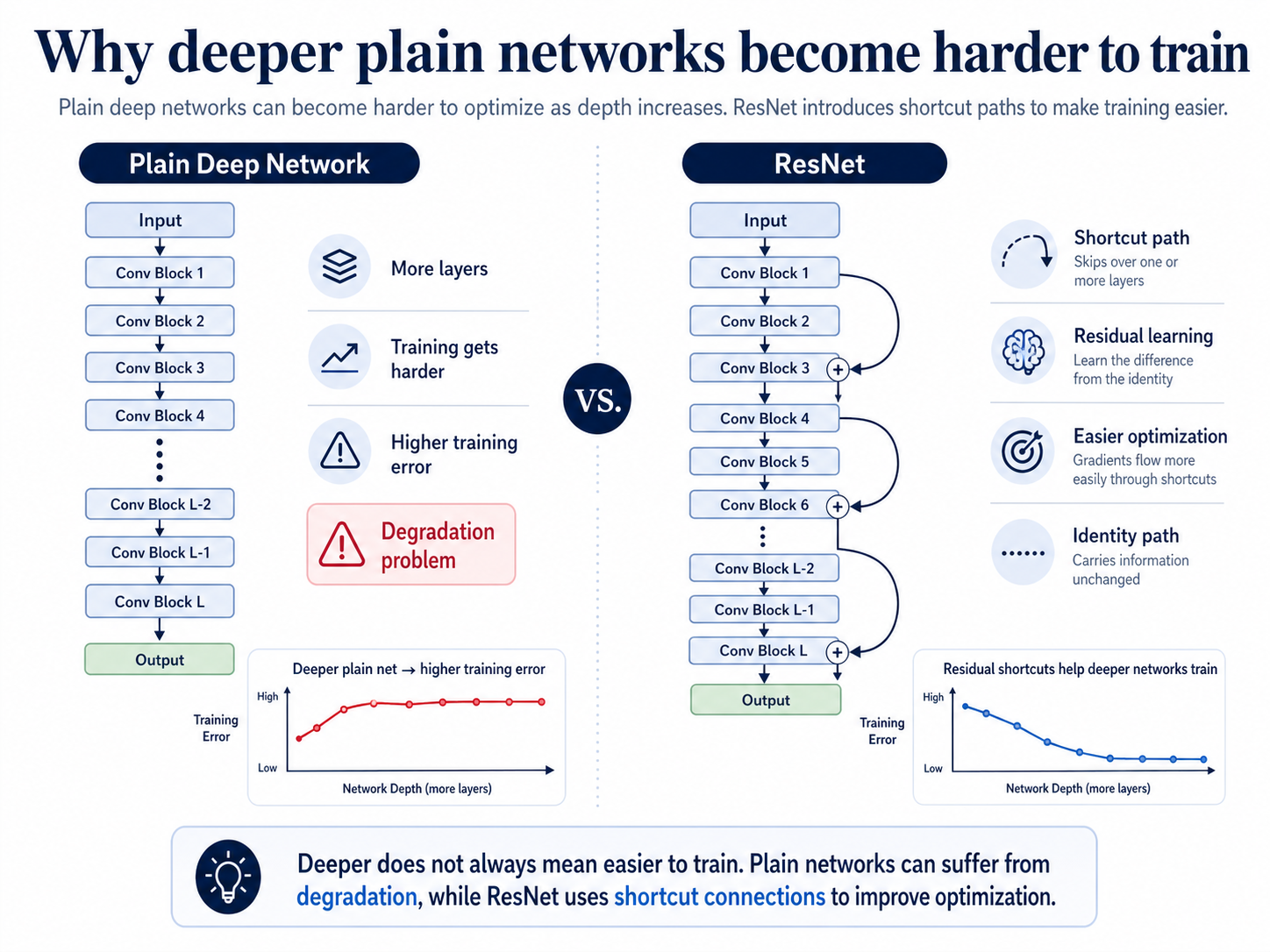
As neural networks get deeper, you might expect them to always perform better, because more layers mean more learning capacity. But in practice, plain deep networks can become harder to train.
After a certain depth, adding more layers can actually make the training error go up, not down. That is the key warning sign.
This problem is called the degradation problem. It is not the same as overfitting. In overfitting, training error is low but test error gets worse. In degradation, even the training process itself becomes worse as depth increases, which tells us the problem is mainly about optimization.
Residual blocks were introduced to make deep networks easier to optimize. Instead of forcing every few layers to learn a complete new transformation, ResNet lets a block learn only the extra change that should be added to the input.
Idea
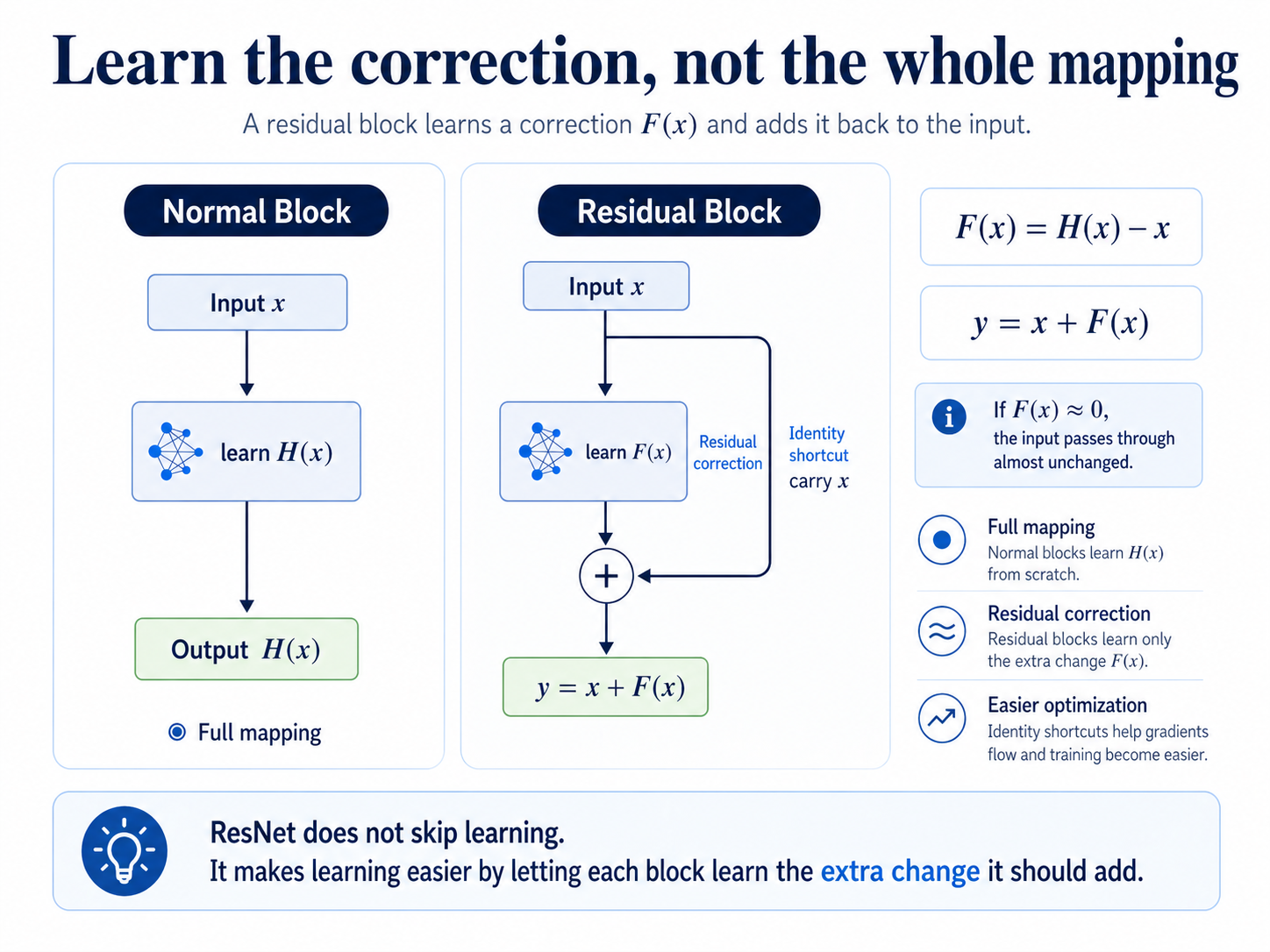
A normal block tries to learn the full mapping H(x). A residual block changes the question.
Instead of asking what whole output should be created, it asks what correction should be added to the input.
That correction is called F(x). If the block is useful, it learns a meaningful correction. If the block is not useful, it can make F(x) very small and simply pass the input forward.
The shortcut path also gives information and gradients a more direct path through the network. During backpropagation, the gradient can move through the identity shortcut in addition to the main transformation path.
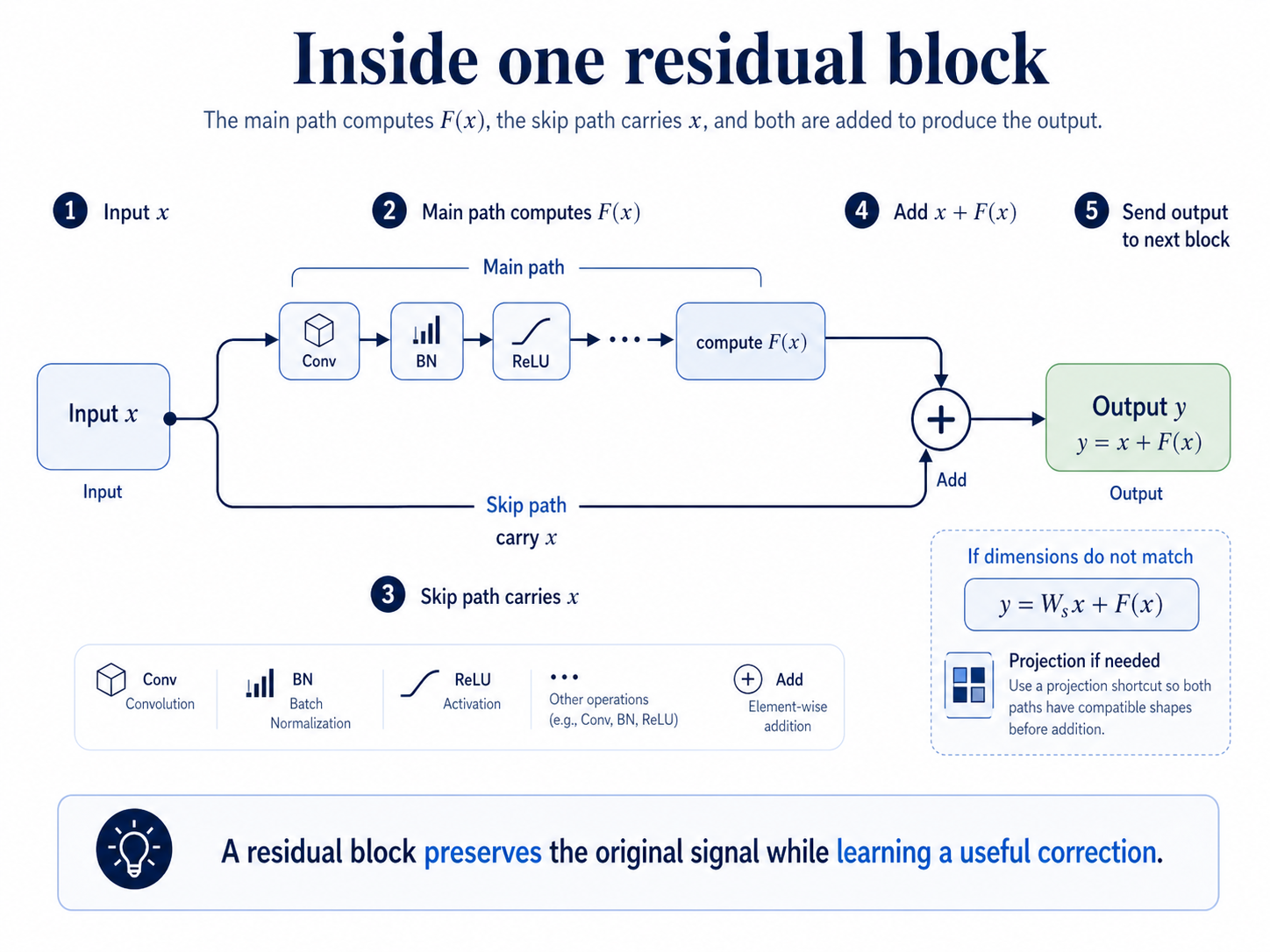
Formula
The full desired mapping the block would ideally learn.
The residual function represents the correction learned by the main path.
The residual block adds the shortcut input to the learned correction.
If dimensions do not match, a shortcut projection reshapes the input before addition.
Symbols
- x: input to the residual block.
- H(x): the full desired mapping the block would ideally learn.
- F(x): the residual correction learned by the main path.
- y: final output after adding the shortcut and the residual.
- W_s: projection matrix or shortcut transform used when dimensions do not match.
Example
Imagine a block receives the feature representation x = [2.0, 1.5, 0.8]. A normal block would try to directly produce the final desired output H(x) = [2.3, 1.4, 1.0].
The residual block instead learns the difference F(x) = H(x) - x = [0.3, -0.1, 0.2]. Then the output is y = x + F(x) = [2.3, 1.4, 1.0].
This is easier to understand because the block is not rebuilding everything from scratch. It is only increasing the first feature a bit, decreasing the second feature a bit, and increasing the third feature a bit.
If the extra layers are not helping much, the block can learn a very small correction. That means a residual block can behave like a small correction module instead of forcing every block to invent a completely new representation.
Workflow
- Input arrives: the block receives input x.
- Main path works: a few layers on the main path compute the residual function F(x).
- Skip path carries the input: the shortcut path keeps x available.
- Addition happens: the block adds the two paths together as y = x + F(x).
- Output moves forward: the result y is sent to the next block.
- If shapes differ: the skip path first transforms the input using W_s, then adds it as y = W_sx + F(x).
Pros
- Enables much deeper networks to train successfully.
- Reduces the degradation problem by making optimization easier.
- Helps gradient flow through identity shortcuts.
- Lets blocks learn corrections instead of full transformations.
Cons
- Does not automatically prevent overfitting.
- Deeper is not always better if the overall design is poor.
- Dimensions must match before addition, so some blocks need projection shortcuts.
- Still needs good architecture, normalization, and optimization to work well.
Takeaway
ResNet does not mean skip learning. It means make learning easier. Each residual block keeps an identity path for the input and learns only the correction it wants to add.
That simple idea makes very deep networks much more trainable. Instead of rebuilding everything at every block, the network can preserve useful information and refine it step by step.