Attention Mechanism
How Query, Key, and Value vectors let a model decide which tokens matter most for the current context.
Background
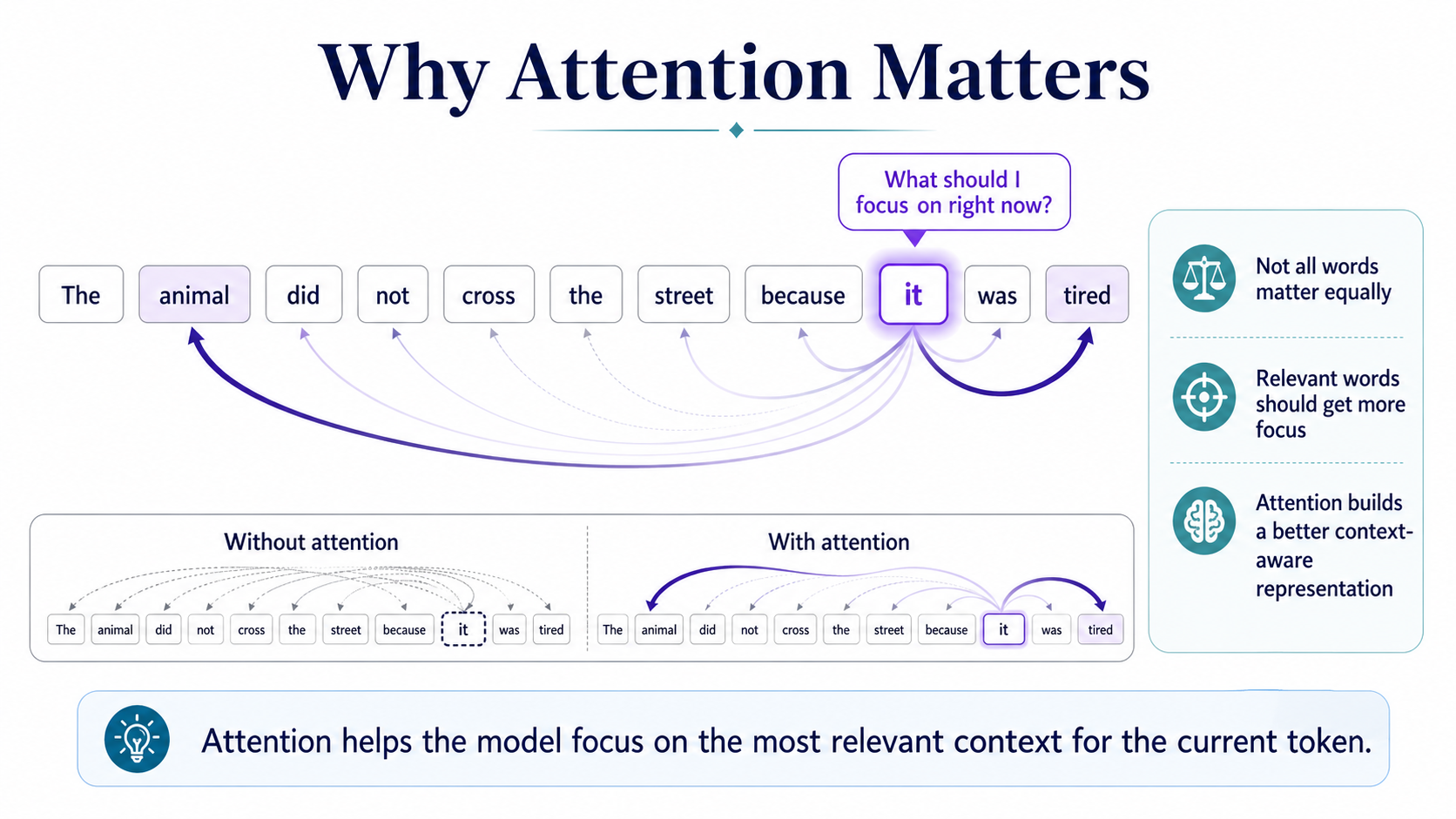
In sequence tasks like translation, summarization, or language understanding, not every word is equally important at every moment.
A model may need to focus strongly on one word while mostly ignoring another. Without attention, important information can be diluted, especially when the sequence is long.
Attention gives the model a way to dynamically decide which pieces of information matter most for the current token or current step. Instead of treating all inputs equally, it computes relevance scores, turns them into weights, and uses those weights to gather useful context.
Idea
Attention answers one simple question: what should I focus on right now?
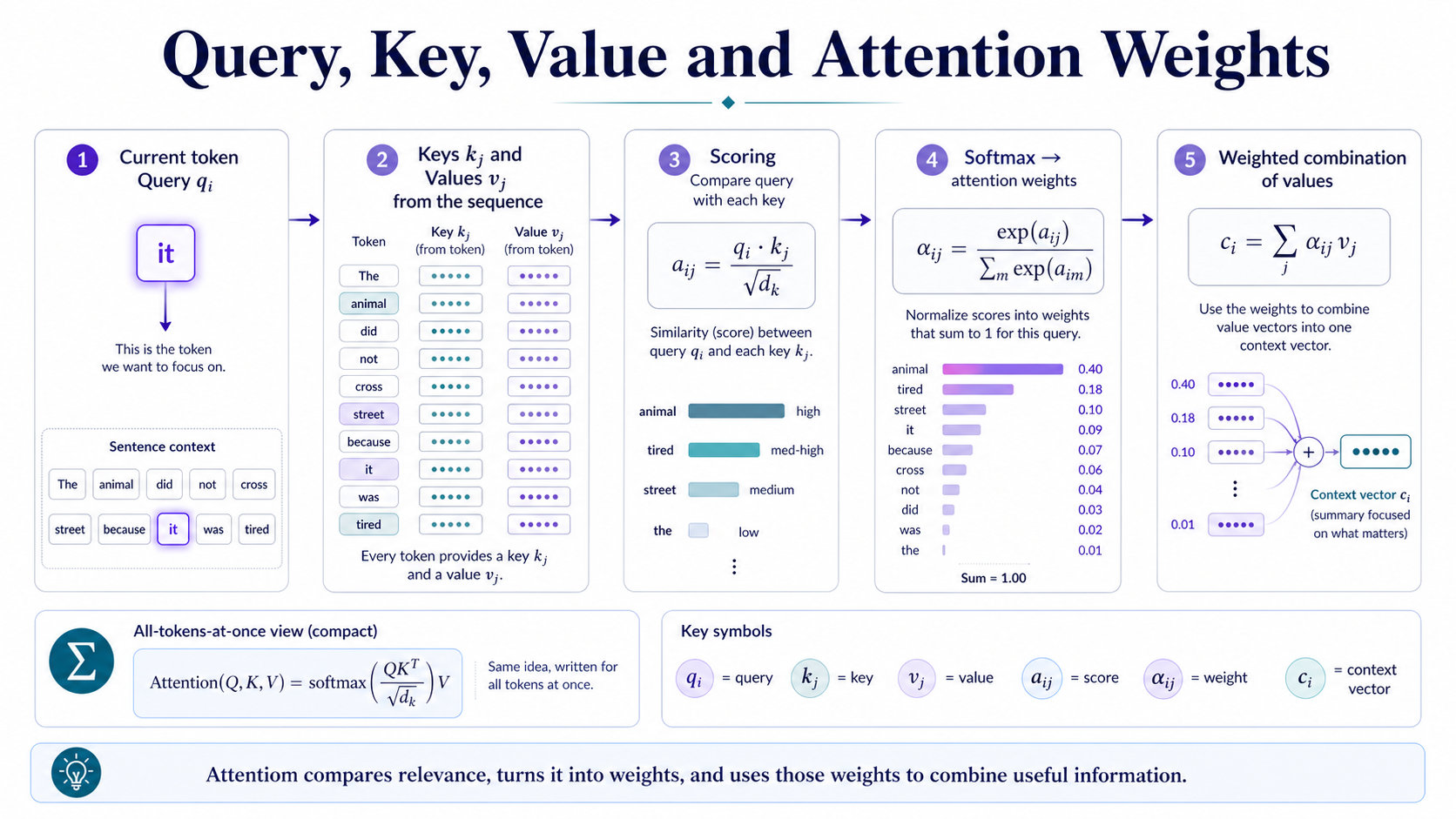
The current token creates a query, which represents what it is looking for. Every token has a key, which represents what kind of information it can offer.
The query is compared with the keys to produce attention scores. These scores are turned into attention weights, and the weights are used to combine the values, which contain the information being passed forward.
The result is a context-aware representation. It does not just represent the token alone; it represents the token plus the most relevant surrounding information.
Formula
A simple dot product measures how similar a query is to a key.
Scaled dot-product attention divides by the key dimension scale to keep scores stable.
Softmax converts scaled scores into attention weights.
The final context vector is a weighted combination of value vectors.
The matrix form applies the same process to all tokens at once.
Symbols
- q_i: query vector for token i.
- k_j: key vector for token j.
- v_j: value vector for token j.
- s_ij: raw dot-product score from token i to token j.
- a_ij: scaled attention score from token i to token j.
- alpha_ij: normalized attention weight from token i to token j.
- c_i: output or context vector for token i.
- Q, K, V: matrices collecting all queries, keys, and values.
- d_k: key dimension used for scaling.
- softmax: turns raw scores into weights that sum to 1.
Example
Consider the sentence: The animal did not cross the street because it was tired.
The token it needs context. It should connect more strongly to animal than to less relevant words like the. Attention helps the model build this connection.
First, the token it produces a query vector. Every word in the sentence has a key vector and a value vector. The query for it is compared with the keys of all words, and more relevant words receive larger attention scores.
After softmax, the scores become attention weights. Since animal has a large weight, its information contributes strongly to the new context vector for it.
Example Attention Pattern
| Word | Attention weight for it |
|---|---|
| The | 0.03 |
| animal | 0.45 |
| did | 0.04 |
| not | 0.05 |
| cross | 0.06 |
| street | 0.12 |
| because | 0.06 |
| it | 0.10 |
| tired | 0.04 |
Workflow
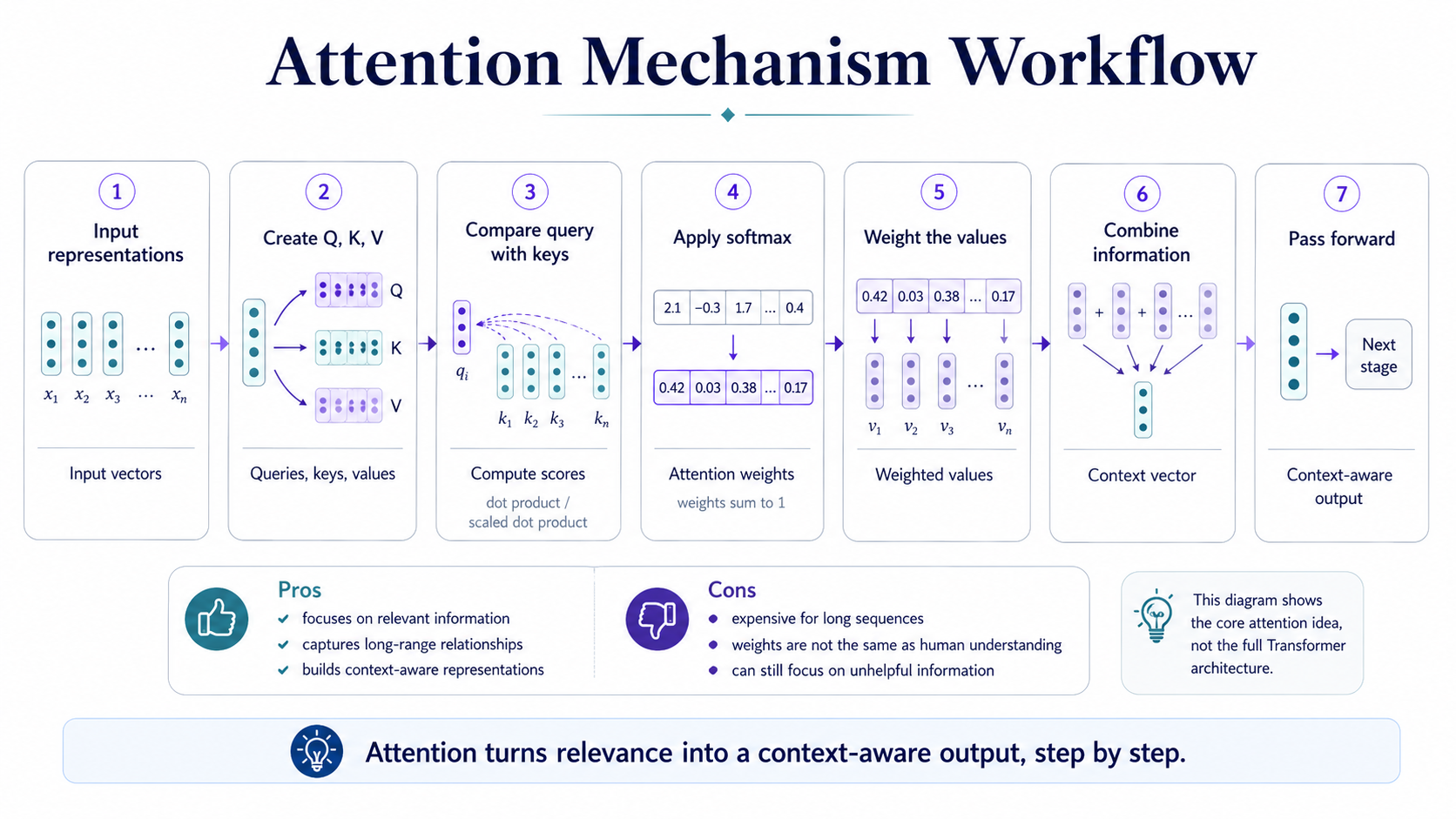
- Start with input representations, usually from an embedding layer.
- Create query, key, and value vectors for each token.
- Compare the query with each key, often using dot products.
- Apply softmax so raw scores become attention weights that sum to 1.
- Multiply each value vector by its attention weight.
- Add the weighted value vectors together to produce a context-aware output.
- Pass the result forward to the next layer or computation stage.
Pros
- Focuses on the most relevant information.
- Handles long-range relationships better than fixed-context methods.
- Produces context-aware representations.
- Flexible and widely useful in sequence modeling.
Cons
- Can be computationally expensive for long sequences.
- Attention weights do not equal true human understanding.
- Poor scoring can still focus on unhelpful information.
- The mechanism can look simple but still be hard to interpret fully.
Takeaway
Attention lets a model decide what matters most right now. It compares relevance, assigns weights, and combines information into a better context-aware representation.
The core idea is simple: score what matters, weight it, then gather the useful information.