Add & Norm
How residual addition and normalization stabilize transformer layers after attention or feed-forward steps.
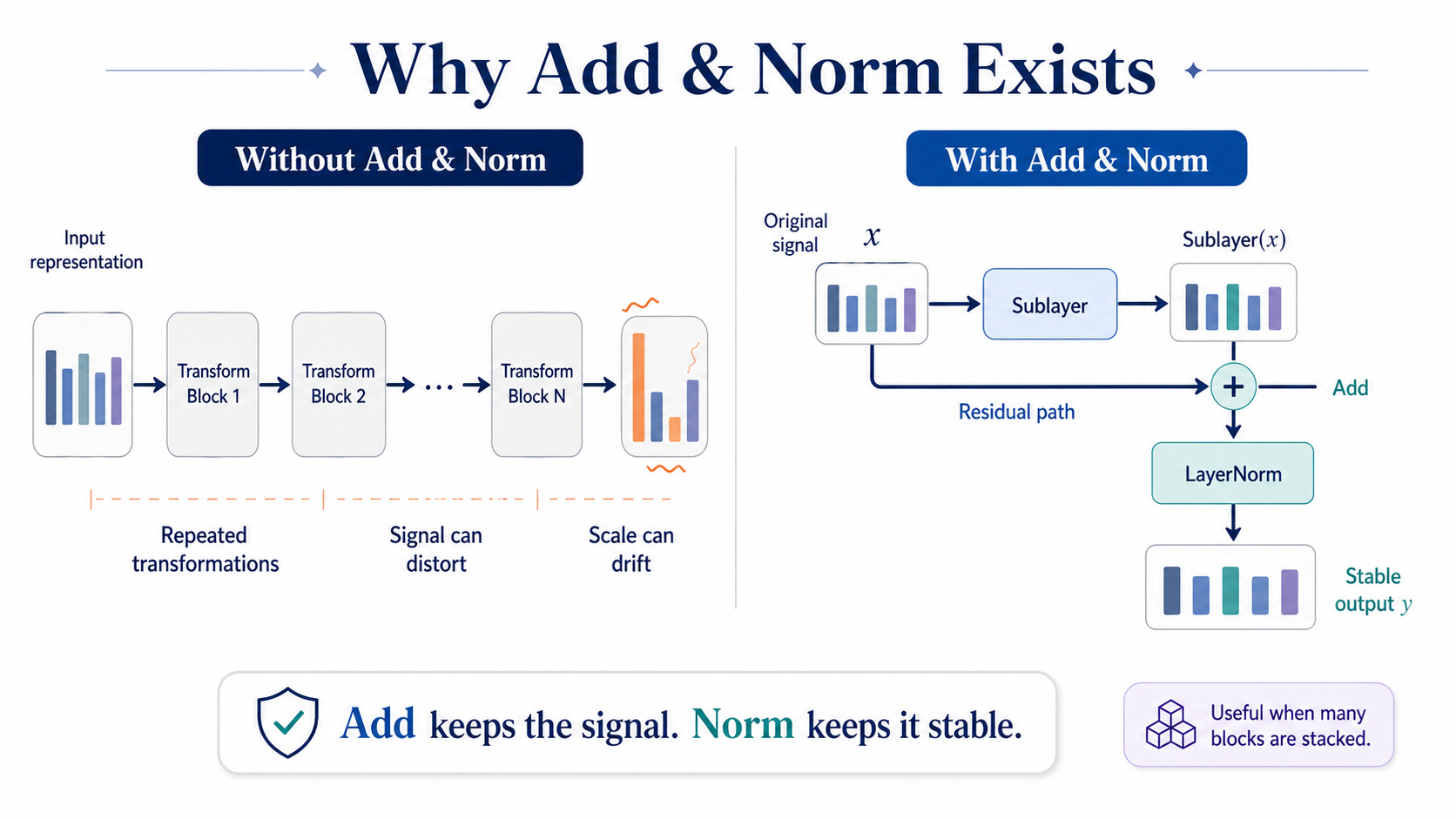
Background
Deep models transform representations many times.
Each block takes an input, changes it, and passes the result forward. This is powerful, but it also creates a risk: useful signal can gradually become distorted, too large, too small, or harder for later blocks to use.
Add & Norm is a small stabilizing step that helps control this. The Add part brings the original input back through a residual connection, so the model does not have to rely only on the transformed version.
The Norm part applies Layer Normalization, which keeps the combined representation balanced before it moves forward.
Idea
Add & Norm combines two helpful ideas.
Add means the original input is added back to the sublayer output. Instead of replacing the input completely, the block keeps a shortcut path for the original representation.
Norm means the combined vector is normalized using Layer Normalization. This keeps the feature values in a more stable range.
LayerNorm is often preferred in sequence models because it normalizes each token representation across features instead of relying on batch statistics.
The mental picture is simple: original signal plus new transformation becomes a balanced output.
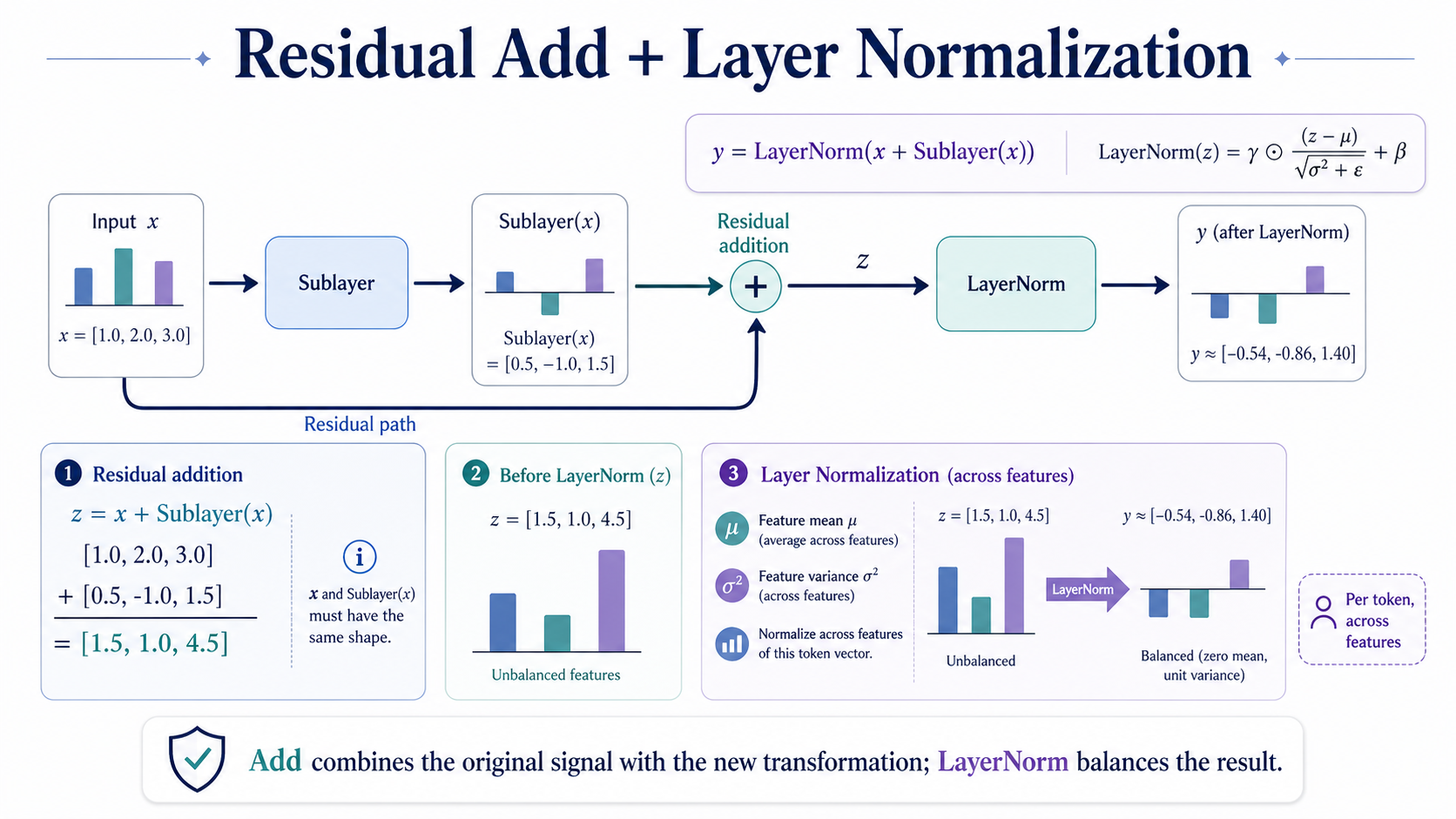
Formula
The main Add & Norm operation adds the residual path and normalizes the result.
Residual addition creates a combined vector.
LayerNorm normalizes the combined vector, then applies learned scale and shift.
The mean is computed across the features of the token vector.
The variance is also computed across the token features.
This beginner-friendly version focuses on the post-sublayer Add & Norm step.
Symbols
- x: original input representation.
- Sublayer(x): output of a sublayer, such as attention or feed-forward.
- z: combined result after residual addition.
- y: final Add & Norm output.
- d: number of features in one token vector.
- z_k: the k-th feature of z.
- mu: mean of the features in z.
- sigma^2: variance of the features in z.
- epsilon: small constant that avoids division by zero.
- gamma: learned scale parameter.
- beta: learned shift parameter.
- odot: element-wise multiplication.
Example
Suppose one token has this 3-dimensional input vector: x = [1.0, 2.0, 3.0].
The sublayer adds new information: Sublayer(x) = [0.5, -1.0, 1.5].
First, add the original input back: z = x + Sublayer(x), so z = [1.5, 1.0, 4.5].
The mean is approximately 2.33, and the variance is approximately 2.39.
After normalization, (z - mu) / sqrt(sigma^2 + epsilon) is approximately [-0.54, -0.86, 1.40]. If gamma = 1 and beta = 0, the output is y approximately [-0.54, -0.86, 1.40].
The original input is not thrown away. The sublayer adds new information, and LayerNorm keeps the result easier for the next block to process.
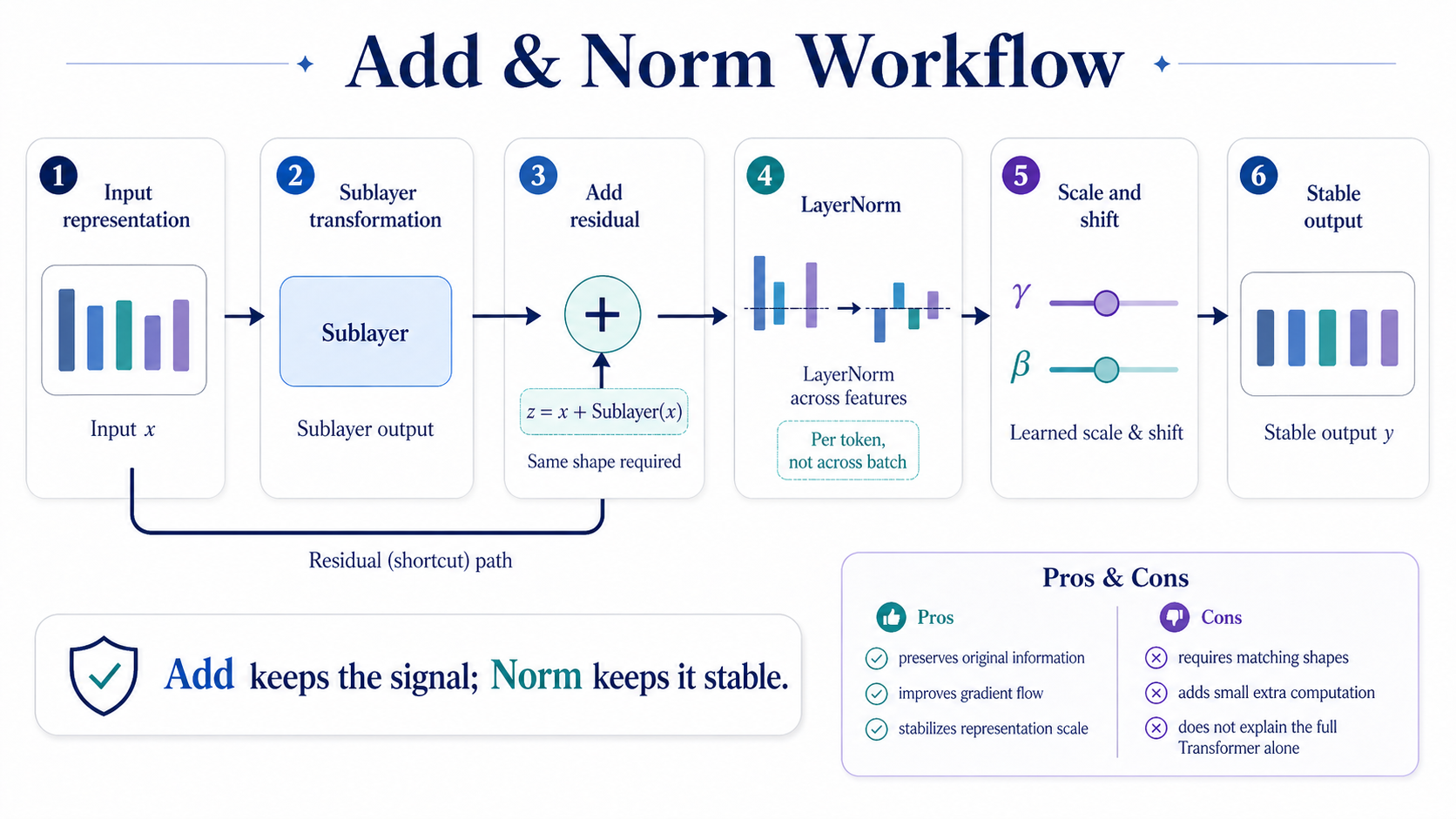
Workflow
- Start with an input representation x.
- Pass x through a sublayer, such as attention or feed-forward.
- Get the sublayer output Sublayer(x).
- Add the original input back: z = x + Sublayer(x).
- Normalize z across its feature dimension using LayerNorm.
- Apply learned scale and shift using gamma and beta.
- Send the stable output y to the next block.
Shape Rule
The important shape rule is simple: x and Sublayer(x) must have the same shape, because they are added element by element.
Pros
- Preserves the original input through a residual path.
- Helps gradients flow through deep networks.
- Makes each block output scale more stable.
- Helps Transformer-style blocks stack more reliably.
- Reduces the chance that one sublayer completely distorts the representation.
Cons
- Adds extra computation and learned parameters.
- Requires matching shapes between x and Sublayer(x).
- LayerNorm stabilizes activations, but it does not solve every training problem.
- Different models may place normalization before or after the sublayer, which can confuse beginners.
- Add & Norm is useful, but it does not explain the full Transformer by itself.
Takeaway
Add & Norm keeps Transformer-style blocks stable.
The Add step preserves the original signal by adding the input back to the sublayer output. The Norm step keeps the combined representation balanced before it moves forward.
Add keeps the signal; Norm keeps it stable.